
What started as a quiet open data revolution has grown exponentially, with governments at all levels liberating their data in open data platforms. Although this is happening across the globe, it was catalyzed in the U.S. by President Barack Obama’s Memorandum on Transparency and Open Government, which led to an executive order that federal agencies publish downloadable data in open formats that are “platform independent, machine readable, and made available to the public without restrictions that would impede the reuse of that information.” In response to this directive, federal agencies developed data catalogs such as Data.gov and HealthData.gov to enable users to search, browse, and access downloadable data more efficiently. Many states and municipalities subsequently developed their own open data portals such as Open NYcovering all New York State agencies, California’s CHHS Open Data covering its Health and Human Services agencies, Analyze Boston, and the Chicago Data Portal. Making data more accessible can encourage data users to repurpose data in innovative ways to improve the well-being of ordinary citizens.
Through an expert review process, the National Committee on Vital and Health Statistics determined that federal open government data “are used by a diverse set of stakeholders to contribute solutions toward HHS [the Department of Health and Human Services] and state government objectives such as identifying quality gaps and health care inefficiencies, enabling researchers to make scientific discoveries, providing communities information about their health problems to inform their community planning efforts, and fostering innovations by entrepreneurs such as for development of applications to assess physicians’ services.” In an earlier post on the OPEN Government Data Act, we describe specific early outcomes of open government data, including improving consumer decision by making it easy to access restaurants’ food safety inspection reports and information on medical providers’ inappropriate prescribing, assisting with the transfer of nursing home patients in Hurricane Irene’s path, reducing Freedom of Information Act requests, and improving the quality of the data itself.

These open data portals and catalogs currently include an astonishing amount of data, with over 3,000 health-related datasets in HealthData.gov alone. However, encouraging diverse data users to visit open data sites and use the data is not as simple as “build it and they will come.” Successful open data platforms start with benchmarking data quality.
How Do We Make Open Data Efforts Successful?
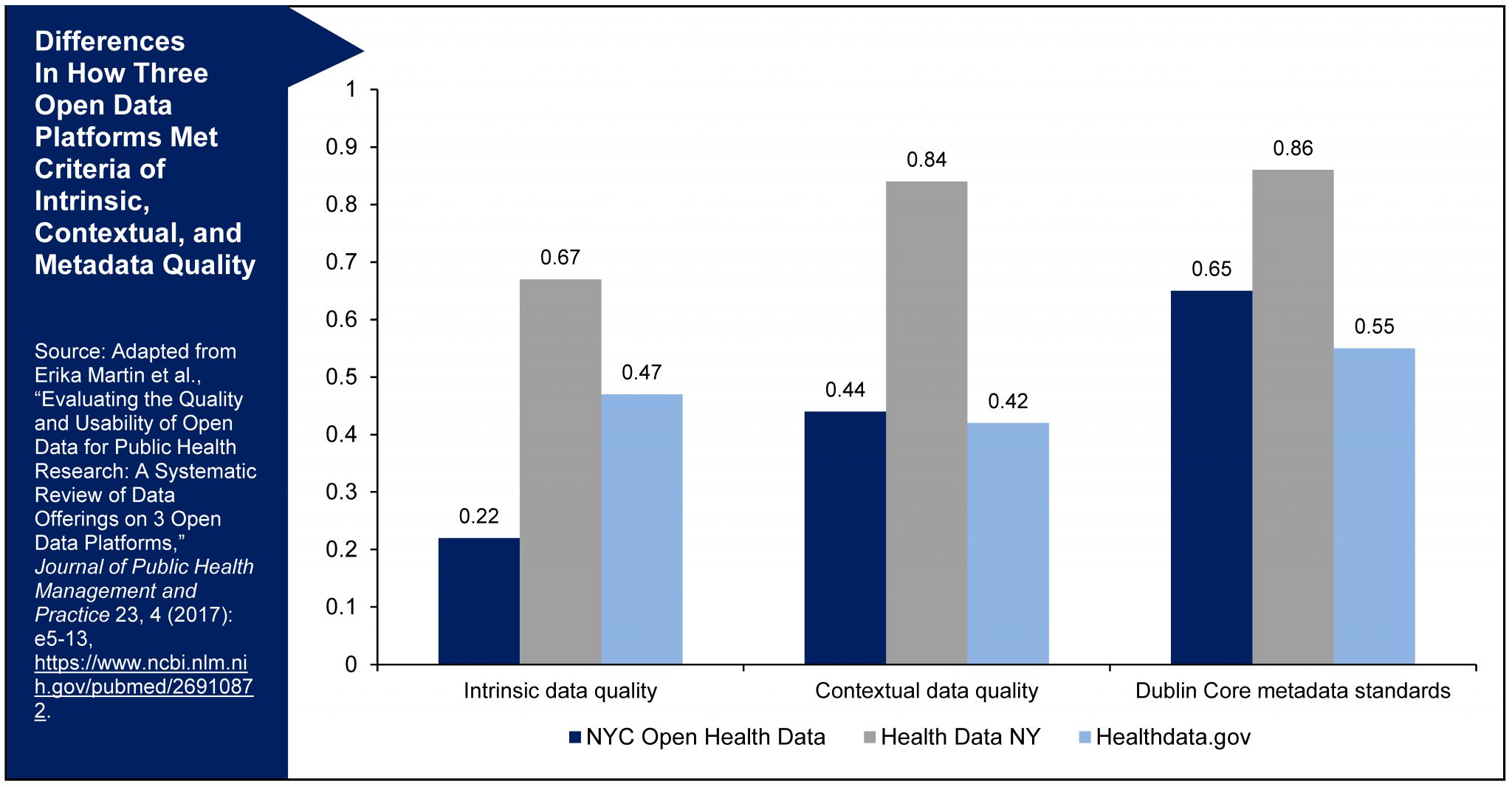
Data quality is commonly measured through intrinsic data quality standards, which are characteristics valued by all users. Important dimensions include accuracy, objectivity, reliability, validity, the believability and reputation of the data producer, and adherence to appropriate confidentiality standards.[1] Although the data are imperfect, we commonly accept birth and death rates published by health departments because they use standardized data collection instruments (birth and death certificates); the data have undergone extensive processing to remove duplicate records, correct reporting errors, and minimize other flaws; the agencies are reputable sources; the statistics are typically reported at an aggregate level such as per county, making it difficult to identify specific individuals; and they are concrete, measurable outcomes. In contrast, there are divergent views about the number of undocumented immigrants in the U.S. and the reliability of these estimates. The nonpartisan Pew Research Center estimates there are 11 million unauthorized immigrants in the U.S., while more conservative groups argue this number is 30 to 40 million. President Trump has asserted that “nobody knows what that number is” and that it could range from 5 to 30 million. This uncertainty is due to the inherent challenges in creating a census of hidden populations, and the highly politicized nature of the issue. Misconceptions and stereotypes about immigration patterns also make it important to understand the data producers and their potential biases.
Beyond these intrinsic data characteristics, there are contextual data quality standards that are important but defined differently depending on the user’s perspective. These components include an appropriate amount of data, completeness, concise representation, ease of manipulation, ease of understanding, relevancy, timeliness, and value-added. A researcher studying the potential effects of environmental toxins would desire individual-level data with specific causes of death, precise geocoordinates, personally identifiable information to link the records to other data sources such as hospital records or education outcomes, and data covering multiple years to examine trends over time. A community planning group may only desire the most recent data in a format that is readily accessible and easy to interpret without requiring further processing, such as the percentage of children in the county with confirmed lead poisoning.
With so many potential data users, it is also important to ensure the quality of the metadata, or the “data about the data.”[2] This includes information about the data producer, time frame, how data were collected and processed, the population covered, and what variables are included. Many open data platforms provide this information in an “About” section that lists each metadata element in separate fields; downloadable codebooks and other supplemental information about the data may also be attached. Metadata are critical to helping data consumers evaluate quality and suitability for their intended use. They can also reduce the risk that data will be misinterpreted, a common fear among data stewards releasing data. Quality standards for metadata include accuracy, completeness, consistency in presenting information, interpretability, and timeliness. International groups have established some minimum standards such as the Dublin Core set of metadata items to include for all datasets. The Health Data NY open data team requires data owners to complete standard metadata templates to provide information to users in a common format.
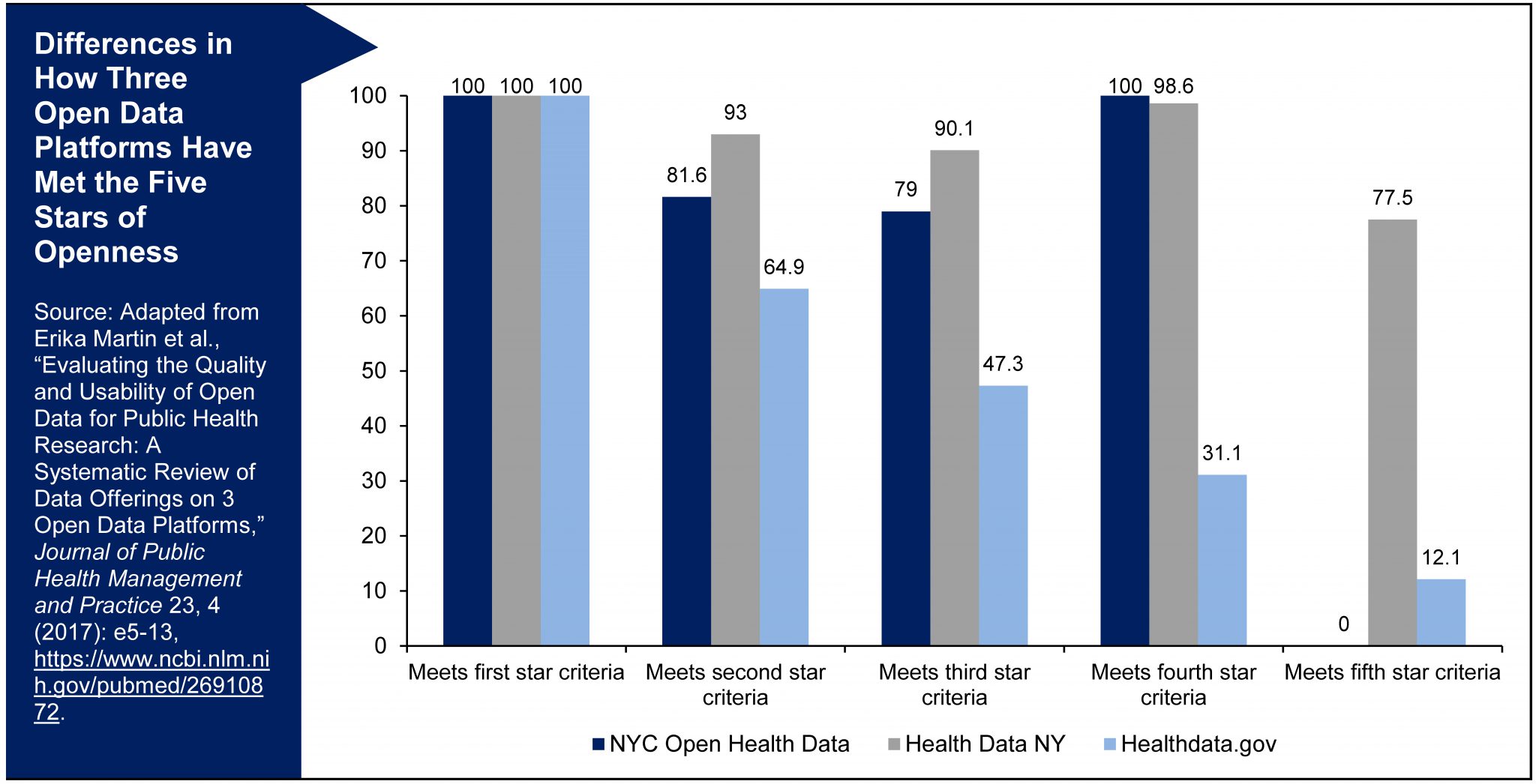
Making open data high quality also requires meeting a fourth standard of degree of openness. Tim Berners-Lee, the inventor of the World Wide Web, provides a useful “five-star” open data deployment scheme. At the low end of openness, “one-star” data are simply available on the web in no particular format. Making data more open entails providing them in structured formats such as Excel spreadsheets that users can reuse (“two-star”), making them available in nonproprietary open formats such as comma-separated values (.CSV) that can be opened in free software packages (“three-star”), providing web addresses or other uniform resource identifiers to enable users to find the data (“four-star”), and linking data to other data to provide context (“five-star”). The 5★Open Data site provides additional information about this schema and examples of how to apply the five stars to data about three-day temperature forecasts in Ireland. This schema is particularly relevant for open data, as posting data in portable document format (PDF) files that are not easily manipulated or as datasets that can only be opened using specialized statistical software make the data unusable for all but the most technically savvy audiences. As open data platforms draw in a diverse group of new users with different skills and interests, providing additional formats and facilitating the discovery of other relevant data is critical to ensuring these new data consumers can discover, use, and understand the data.
How Do Existing Open Data Stack Up to These Quality Standards?
There are many areas where open data currently fall short of these quality standards. In a recent journal article, one of us systematically examined data offerings in three open data platforms (HealthData.gov, Health Data NY, and NYC Open Data) and found many areas for improvement. Only one-quarter of the data offerings across these sites had structured datasets as their primary presentation format. Only three-quarters of New York State and New York City offerings and one-third of federal offerings could be easily viewed, with the remaining datasets requiring users to download external files to open in statistical software programs, located on external web pages that were difficult to navigate, or not being available at all. On average, the data offerings only included around two-thirds of the metadata elements that were assessed in the study. By being discoverable in the open data portals, all data offerings automatically met the first of the five-star criteria of being available on the web. However, only one-third of the offerings met all five openness criteria.[3]
Producing and disseminating high-quality open data that meet these standards is not easy or cheap. From our conversations with leaders and practitioners releasing open data, barriers to releasing data that can achieve these quality benchmarks include:
- Limited human resources, including staffing and technical skills relevant to open data;
- Cultural resistance to publishing government data in new open formats;
- Legal and regulatory issues that limit how data can be released;
- Tensions between including enough information to be valuable to many users while minimizing disclosure risks;
- Relying on local partners to collect data, which may result in variable intrinsic data quality;
- Technical difficulties extracting data from legacy software systems;
- An incomplete understanding of data users, their desired formats, and how to customize data to meet their needs; and
- Knowledge gaps within agencies about open data principles and how to tailor data products for open data platforms.
The 5★Open Data site summarizes additional barriers that data producers may face in publishing data with high levels of openness:[4]
- Publishing three-star data requires tools to convert data from proprietary to open formats;
- Publishing four-star data requires additional time to establish and assign uniform resource identifiers; and
- Publishing five-star data requires time to link data to other information on the World Wide Web, and continued maintenance to repair broken or incorrect links.
Publishing five-star data also requires an understanding and expertise with linked open data technologies, such as the Resource Description Framework and other semantic web technologies, and maintaining the data according to best practices.
Benchmarking data to these high standards of data quality, metadata quality, and degree of openness is aspirational. The expertise and resources required to achieve these standards — which delays the pace of opening government data — also needs to be weighed against the value of releasing earlier versions of incomplete “provisional data” to improve the timeliness of data release.[5] However, keeping these data quality benchmarks in mind can help government agencies promote their use to maximize the value of their data in this new open data era. As data quality is only one component of successful open data platforms, in future posts we will explore other topics such as: (1) how to make platforms more usable and engaging to encourage data enthusiasts to visit and return to open data sites, (2) the potential risks and benefits of releasing earlier provisional data, and (3) diverse political opinions about the value of opening government data.
[1] For a more detailed review of the four data quality standards, see Martin et al., “Evaluating the Quality and Usability of Open Data for Public Health Research: A Systematic Review of Data Offerings on 3 Oen Data Platforms,” Journal of Public Health Management & Practice23,4 (2017): e5-13, https://www.ncbi.nlm.nih.gov/pubmed/26910872.
[2] For a more detailed description of metadata, the National Information Standards Organization provides a useful primer.
[3] For this study, the fifth star criteria was evaluated with a much less stringent criteria than the technical definition of linked open data, which is data that is linked to other data on the Semantic Web using uniform resource identifiers and resource description framework specifications.
[4] The site also describes the costs and benefits faced by data consumers as data have increased levels of openness.
[5] The National Committee on Health and Vital Statistics provides a more detailed description of how releasing early provisional data, where appropriate, can be useful for improving the usefulness of the data.